
RAG: What is it and how to use it
An explanation to today's latest trend

👋 Hey, it’s Orel here! Welcome to my weekly newsletter where I share my journey and lessons as a solopreneur who quit his 6 figures job to chase his dreams.
RAG is one of the latest trends in the AI world.
Everywhere you turn, the best products use RAG to generate your content, and they charge a high price for it.
In today’s article we’ll learn what’s RAG and how you can do it too.
Introduction to RAG
ChatGPT (The new wikipedia):
RAG stands for Retrieval-Augmented Generation, a powerful approach that combines the ability to search through specific knowledge bases with AI's natural language capabilities.
For solopreneurs, this means having an AI system that can read your business documentation, or your scraped tweets database, to provide more relevant and accurate responses.
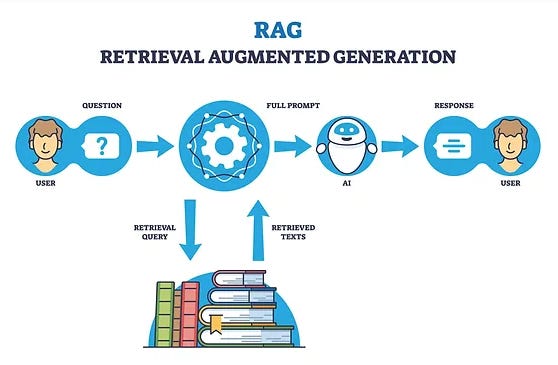
Core Components
Knowledge Base: Your database - containing documents, FAQs, product information, or any other relevant data.
Retrieval System: The search engine that finds the most relevant information from your knowledge base.
Language Model: The AI that takes the retrieved information and crafts it into coherent, natural responses.
How RAG Works
Imagine you scraped millions of LinkedIn posts. When a user asks for viral content insights, here's how RAG works:
The user asks what type of posts get the most engagement in the AI industry.
The retrieval system quickly searches your massive LinkedIn post dataset, analyzing patterns in likes, comments, and shares.
The LLM combines this real-world data with its general knowledge about LinkedIn algorithms and content trends.
The result? A precise, contextual answer backed by actual engagement metrics, not just generic advice from the lLM.
By using RAG you combine the power of an LLM with the relevant knowledge from your database.
But wait
You might think to yourself:
That sounds nice, but searching through millions of tweets will take a very long time.
And you’re correct. That’s why we don’t query your postgres or mongo db.
Core components of RAG
1. Knowledge Base (Your Data)
This is where all the relevant information is stored. It can include:
Structured Data: Databases, APIs, product catalogs.
Unstructured Data: PDFs, research papers, FAQs, chat logs, blog posts, scraped web data.
Embeddings Database: Documents and text chunks transformed into vector representations for efficient retrieval.
2. Retrieval System (Search & Indexing)
The retrieval system quickly finds relevant documents or data chunks based on user queries. It typically includes:
Vector Database (e.g., Milvus, Pinecone, Weaviate) – Stores and searches embeddings.
Hybrid Search (BM25 + Vector Search) – Combines keyword-based search (BM25, Elasticsearch) with vector similarity search for better results.
Indexing & Chunking Strategies – Splitting documents into smaller, meaningful chunks and indexing them for efficient retrieval.
The most common and easy way to do it is using a vectorized db. Searching through millions of rows takes a few milliseconds.
3. Language Model (LLM for Generation)
Once relevant documents are retrieved, the language model processes them to generate the best and most accurate response.
Common use cases for RAG
Advanced Question-Answering Systems: RAG models power systems that retrieve and generate accurate responses, enhancing information accessibility for individuals and organizations.
Educational Tools: RAG enhances educational tools by providing personalized learning experiences, retrieving and generating tailored explanations, questions, and study materials.
Information Retrieval: RAG improves the relevance and accuracy of search results, enabling search engines to retrieve documents or web pages based on user queries and generate informative snippets.
How to start building your RAG
1. Build your database
The first thing you need to do is have a database with all the information you need, be it tweets, linkedin posts or your product’s description.
2. Build your vectorized database
Use Huggingface library or OpenAI API to embed your data and save it into a vector database (Supabase, Milvus, Pinecone etc.)
Embedding means that a model translates your data's context and meaning into an array of numbers
3. Build a flow of searching + prompting
Now that you have your vectorized db ready, you can run queries on it and use the data retrieved to prompt an LLM to get great results.
Example:
Query tweets vectorized db: ‘How to build SaaS’ → get related tweets → Prompt LLM with the related tweets to generate a new tweet.
Final words
Understanding the concept and building a RAG system feels hard in the beginning, but once you understand it’s power and how to use it, it’s amazing.
I am working on a tool to help you overcome your writer’s block and generate ideas + outline for new articles based on your Substack data and best articles in the genre.
More on that soon!
Thanks man, useful to what am building right now. I was chatting with AI and trying to figure out which framework to use. And this what l was looking for
Thanks for the mention 🙏🏻